Ever since the beginnings of natural language processing starting with the Turing test, understanding human language has remained one of the most sought after achievements in artificial intelligence. Human languages are varied and complex and have evolved over thousands of years resulting in thousands of languages and dialects. Linguists can group and trace languages back to fundamental root languages, forming language trees such as the Indo-European and Uralic language families illustrated below.
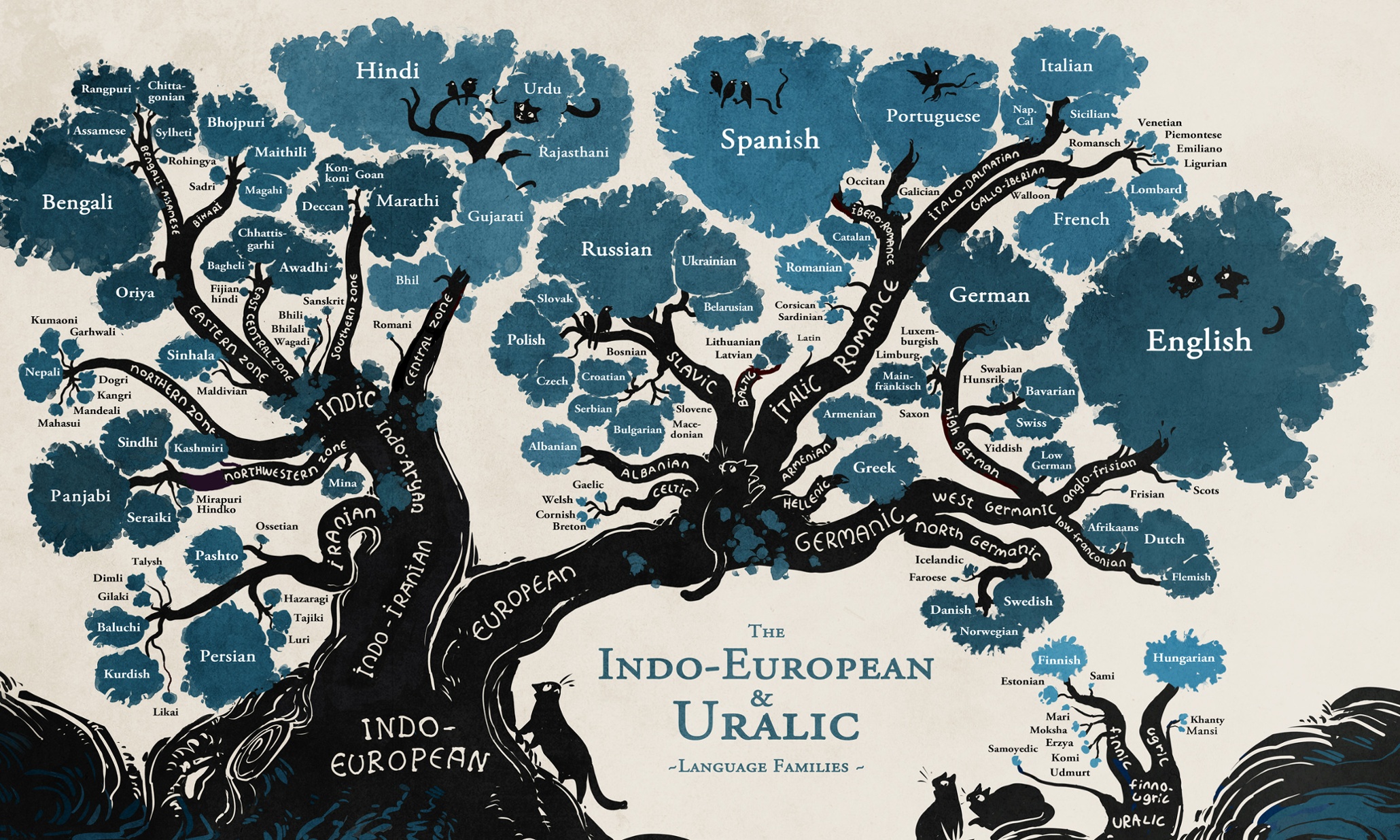
Though just because a language is closer to the root, such as Latin to European Romance languages or Sanskrit to many Indian languages, doesn’t necessarily mean it is more fundamental such that it would be easier to process by a NLP system. Many attempts have been made to create simpler and more expressive languages, though none have all the properties of the mythic Universal Language. Some such invented languages include Esperanto, Lojban, Blissymbols and Basic English.
Basic English was designed to have only 850 words and a simplified grammer such that it could be easily learned and spoken globally. This appears at first to be a noble proposition, however it later inspired Newspeak which was introduced to the people of Oceania in the book 1984 as an attempt to control the population by limiting the ideas possible to express.
The Sapir–Whorf hypothesis proposes that the way people think is profoundly affected by the language they use. These language features include what is easy to express, what is difficult to express, and what must be expressed as a consequence of using the language. For example, English requires personal pronouns to have gender: he, she and it. In contrast, spoken Chinese makes no distinction as these are all pronounced “ta”. In the science fiction novel Babel-17 a language itself was weaponized as learning it acted as an intellectual contagion.
All of this complexity poses difficulties for natural language processing. In order to truly understand language it is first necessary to have the context of the world in which it exists. However, providing a computer with this context is quite difficult. Most modern machine translation systems take advantage of statistical models or more recently deep learning, however back when computers were less powerful and there was less data available, a linguistic approach was taken involving linguistic rules. A famous early example of this approach was used in the Georgetown experiment in 1954.
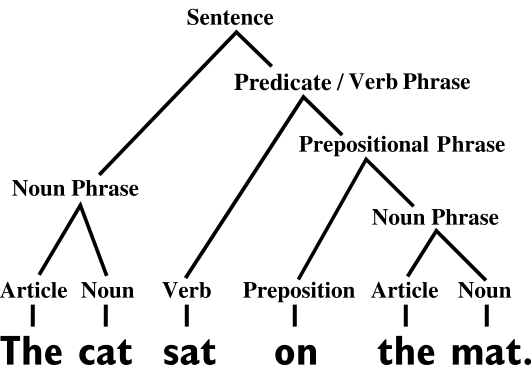
In this approach the text is first represented according to syntactic rules, the structure of the sentence, such as the sentence “the cat sat on the mat” shown below. This is then used to derive the semantics, the meaning of the sentence.
This approach seemed the best place to start in deriving sentiment from the 2015 Reddit comments corpus for named entities, such as organizations, if only to compare to more modern approaches. The source for this is available on github.
First, all comments for the month January 2015 was downloaded from the 2015 Reddit comments corpus, which was extracted on “Sat, 28 Feb 2015 11:50:07 GMT”. Next, to build the pipeline. The data was loaded into S3 where it could be easily processed and aggregated by Spark. Once this is complete Spark can be run using AWS EMR. Next, to parse the sentences. CoreNLP is a great choice for performing the initial NLP steps of tokenization, part of speech tagging, stemming, and named entity recognition.
These steps will first separate the sentences into tokens and tag them according to their type, “orange” is tagged adjective (JJ), “cat” is tagged noun (NN) etc. Stemming converts all words to word stems, “am”, “are”, and “is” becomes “be”, “walk”, “walked”, “walks”, and “walking” becomes “walk”. Named entity recognition (NER) marks if a noun is a special type, such as an organization.
CoreNLP has more advanced features, including sentence parsing and it’s own sentiment analysis. However, since only single entities, not whole comments are being considered, and this is a hefty task given every comment must be parsed, these were not included in the pipeline.
Now to apply our simple linguistic rules, these are direct adjectives of the form “adjective noun” and connected adjectives of the form “noun is adjective” to start. This can be illustrated with some examples generated using the CoreNLP demo.
Direct Adjectives
"The blue dog ate lasagna"
The/DT blue/JJ dog/NN ate/VBD lasagna/NN
(ROOT
(S
(NP (DT The) (JJ blue) (NN dog))
(VP (VBD ate)
(NP (NN lasagna)))))
Connected Adjectives
"The dog is blue"
The/DT dog/NN is/VBZ blue/JJ
(ROOT
(S
(NP (DT The) (NN dog))
(VP (VBZ is)
(ADJP (JJ blue)))))
Also word articles like “a” and “the” are ignored, the conjunction “and” is used for combination, and sequences of adjective modifiers and adjectives are applied to full nouns which may consist of multiple words. These results can be seen below in a table built for this purpose using React, Redux, Immutable, and Webpack. The table can be filtered by entering in the input and sorted by clicking the column title.
From here it is possible to filter to desired organizations, Subreddits and adjectives. For example filtering by “AMD” organization, the “pcmasterrace” Subreddit considers them “cheaper”, whereas “buildapc” Subreddit also says “just as good”. According to the “DotA2” Subreddit the “valve” organization is “lazy” but also “smart”.
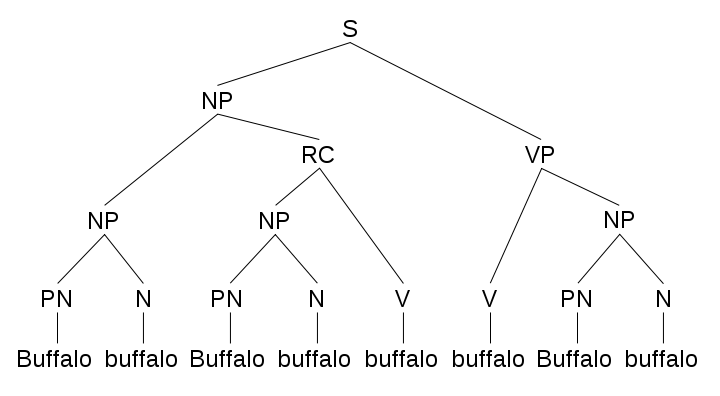
Though of course these linguistic rules are simplistic and would certainly not be able to properly parse a sentence like the buffalo sentence. Though humans have difficulty with this sentence as well.
And even when the parsing is correct according to the syntax, that doesn’t necessarily lead to meaningful semantics, as is the case for the sentence “Colorless green ideas sleep furiously”.

However, for the simple case, simple parsing is sufficient. Though this can be greatly improved using neural network algorithms such as Word2Vec which is explored in the next post.
Links:
1) Spark analysis
2) Customizable table