
This post is a continuation of NLP on Reddit in which Spark is used with CoreNLP to gather sentiment on organizations from the Reddit comment corpus. Although traditional natural language processing is a natural way to derive meaning from sentences, when using an algorithm such as Word2Vec it is not necessary to provide tagging, parsing or deeper information about English because the algorithm only considers the word contexts.
As the name sugests, Word2Vec is designed to convert words to a vector of numbers representing that word’s semantic meaning. This is to say, if the vectors of two words have a high cosine similarity those two words would be expected to be semantically similar. Semantically similar here means that one word has a high probability of being a possible drop in replacement of the other word within the corpus text. For example, in most texts run through Word2Vec, the vector for “boy” would have highest cosine similarity to the vector for “girl” because one could be a replacement for the other.
Another similar word to both might be “teenager”, whereas “boy” would also have high similarity to “man”, but not to “woman” and “girl” would have high similarity to “woman” but not to “man”. From this it is possible to form a manner of semantic arithmetic. The phrase “man” is to “king” as “woman” is to “queen” can be written as below.
It is also possible to then cluster words by meaning by clustering their vectors using a method such as K-means. So given the words, “cat” “dog” “hamster” and “documents”, “documents” would be marked least similar. This method is applied to the movie reviews sentiment analysis Kaggle dataset in their Word2Vec NLP tutorial, which ultimately uses Gensim and K-means to cluster words and derive sentiment. This tutorial also explores Gensim further and provides some examples.
Spark offers its own implementation of Word2Vec which can be used with the ML pipeline, which will be a good match in applying to the Reddit comment corpus for January 2015. The source for this is available on github.
In order to produce these word vectors, Spark uses the Skip-Gram model. The variables represent the words in the corpus used and is the size of the training window, i.e. the context words to either side of the target word. The negative cost function is written below. The goal is to maximize the average log-probabilities of a word being used in its proper context of words.
The probability of predicting the word given the word is the softmax model as stated below. In this equation is the vector for word and is the vector for the context of word . is the total vocabulary size.
The diagram below from Tensorflow Word2Vec shows how the context words are used to deduce the target word. The context is used to produce softmax classifier results, the highest probable word of the vocabulary is then selected.
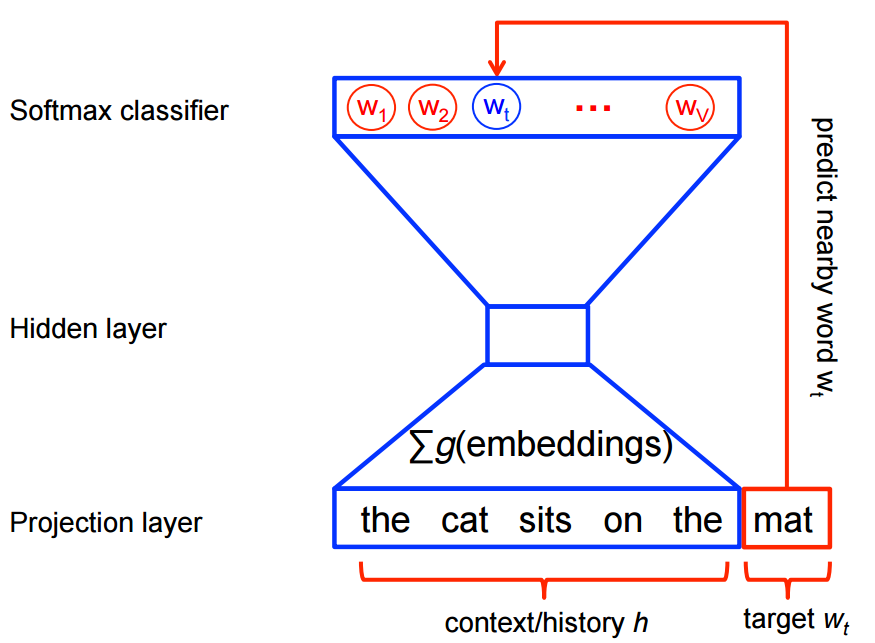
This can be sped up by using hierarchical softmax which avoids calculating the full probabilistic model, instead focussing on the most probable target words, and not including noise words.
There are a number of parameters that need to be specified before running Word2Vec. The vector size of each word chosen for the Reddit model was 300 and minimum number of word occurrences required before being included was set to 10. Below are the Word2Vec results shown with a react table built for this purpose. The table can filter via the inputs or order rows by clicking the sortable column headers.
Many interesting features can be derived from this including how competitors or related entities so often line up, “Nintendo” to “Sega”, “NFL” to “NBA”, “Disney” to “Pixar” etc.
Other options available for performing Word2Vec include Torch, Tensorflow and Deeplearning4j. Another common algorithm for word vector representation is GloVe. Overall, vector representation of words is a burgeoning tool for semantic analysis.
Resources:
1) T. Mikolov, et al. Efficient Estimation of Word Representations in Vector Space, 2013
2) T. Mikolov, et al. Distributed Representations of Words and Phrases and their Compositionality, 2013
3) Y. Goldberg, et al. word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method, 2014