
Generative adversarial networks are ideal for producing deceptively convincing invented media when given only a set of training media. GANs do this by utilizing a pair of dueling neural networks, one , the detective network, being trained to detect counterfeit media generated by the other network , and the other network , the counterfeiter network, being trained to trick into thinking its generated media is from the training set. This process can is essentially a game, like tic-tac-toe, and can be solved similarly using minimax, optimizing for each player each turn. The example on the left shows generated living spaces.
We can apply this same GAN technique to the problem of matching mouth movement to an audio dub, resulting in a more realistic dubbing. This is done by first creating and from the genuine video and audio, where all that is generated is the expected face shape given the audio and background. Then feeding the foreign audio dub through the generator to get the new generated video file to match the foreign audio dub.
Preprocessing techniques such as audio spectrograms and 3D facial modeling can also be applied.
The diagram below shows the creation of and .
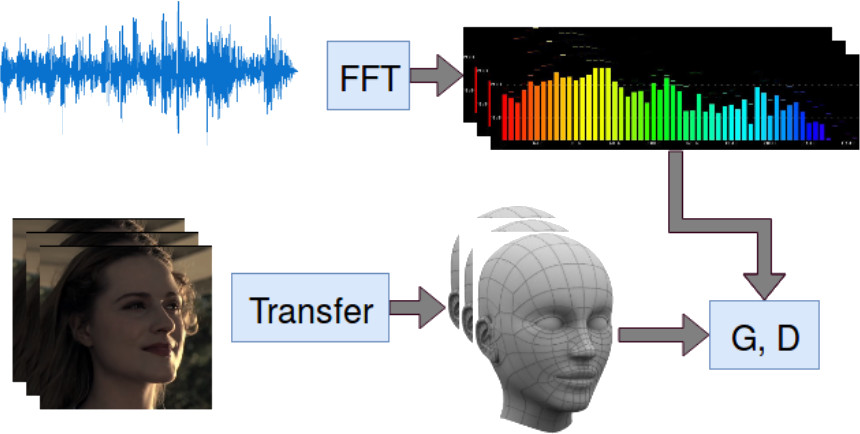
The following diagram shows utilizing , the original media, and the foreign audio dub to generate the new dubbed media.
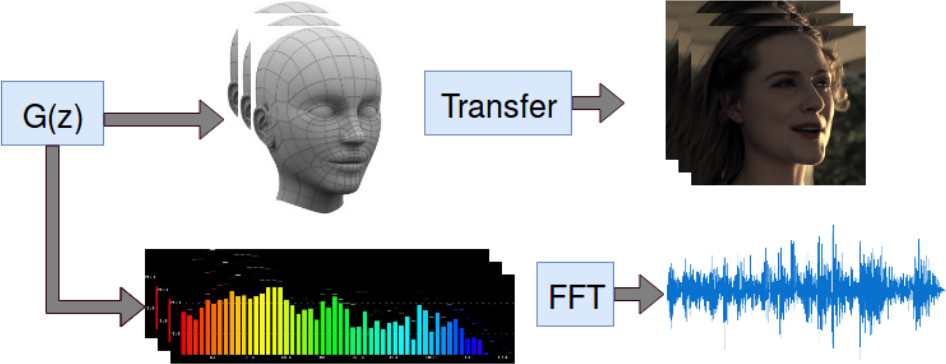
These processes are further formalized in this paper.
A large amount of correctly subtitled media is required for this method to be effective. In this arena, Fluency Rodeo can greatly help.