
New advances are continually being made in machine learning algorithms, improvements in recurrent and convolutional deep neural networks being some of the most notable recent examples. However, it’s often not the quality of the algorithm or even the quality of the data that leads to the best results, but the sheer amount of data that can be brought to bear against a problem.
"It's not who has the best algorithm that wins, it's who has the most data."
- Andrew Ng
As presented near the end of the excellent Machine Learning Coursera course, the graph below shows a small example of the data quantity vs. result accuracy phenomena in action as applied to the subject of Natural Language Disambiguation. Although there are diminishing returns, often in ML research getting a 75% prediction accuracy is easy whereas getting to 90% is near impossible, we can still see that the algorithms used don’t impact the results effectiveness nearly as much as the amount of data does.
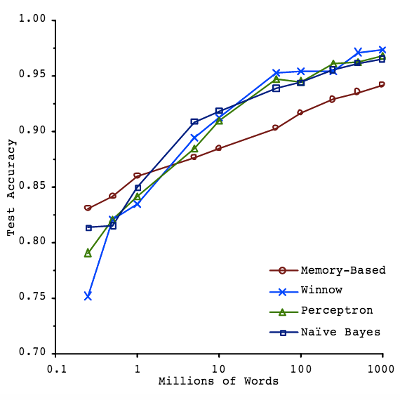
Another way of phrasing this is that when the amount of data is small, most techniques used will inevitably overfit the provided examples unless pressure is explicitly applied, such as regularization, to prevent this. For example, A polynomial exists that can exactly match any n-dimensional set of values, however it almost certainly will not generalize to new values even if they follow the same general pattern as the original values because the model would be so hyper focussed on matching the training examples.
One could make an analogy here to the notion of perspective. Anyone brought up in a certain context, though well suited for its particular nuances, will be woefully unprepared, Prince and the Pauper style, for dealing with a new context.
Overfitting is a common problem in statistics where practitioners know if data is worked on long enough, it is possible to force it to say almost anything. One of the primary impediments to forming meaningful predictions based on historical data is the correlation vs. causation problem. Based only on a narrow set of information it is difficult to determine cause and effect.
There is a study targeted towards MBA finance students that shows an excellent correlation between butter production in Bangladesh and the S&P 500 Index between the 80s and 90s, but for any other years there is no correlation. This exemplifies the fact that there can exist strong correlations that don’t have any deeper meaning or explanation. This study also demonstrates that even reasonable theories that are propped up by supporting data may in reality be no more meaningful than butter to stock prices when viewed with greater context.
Correlation vs. causation problems appear all over the modern world. For example, in the case of finance it is of paramount importance to properly understand causation. Connections like: bad whether leads to low wheat production which implicates higher wheat prices which provokes unrest in the Middle East leading to low oil production and high oil prices. However, as complex as these connections can be, in the case of the stock market it’s also important to consider what the other traders, human and machine, think, and what they think other traders think and so on. This is one reason why oil prices continue to rise even when there is plenty of oil.
This meta-consideration is part of what makes the question of twitter funds interesting. Supposedly it is possible to track the mood of the general public using twitter and use it to predict stocks. Even if the study is flawed, it remains valid if traders believe in it and thus make it true. For instance when there was a lot of buzz around Anne Hathaway, the stock for Berkshire Hathaway shot up because trading machines saw a lot of positive talk about Hathaway and assumed the Berkshire Hathaway stock would rise. It made no difference whether in actuality it was Anne or Berkshire, the stock still went up in the short term.
This is part of what makes short term and high frequency trading unpredictable, it doesn’t matter if value is real or not. This isn’t all that surprising given that markets in general run almost entirely on faith. This is also why there are flash crashes involving trigger happy machines and fear filled traders. When asked about this, George Soros admitted the irony of hedge funds protecting investors from market volatility that hedge funds themselves create.
It’s hard to know whether the correlations being looked at are really predictive, or just random. Ultimately, the world is complicated and is often impossible to boil down to easily digestible ideas and sometimes it can’t be boiled down to anything at all. Though having more data and greater context certainly helps.